LINUX
GNU/Linux es uno de los términos empleados para referirse a la combinación del núcleo o kernel libre similar a Unix denominado Linux con el sistema GNU. Su desarrollo es uno de los ejemplos más prominentes de software libre; todo su código fuente puede ser utilizado, modificado y redistribuido libremente por cualquiera bajo los términos de la GPL (Licencia Pública General de GNU, en inglés: General Public License) y otra serie de licencias libres.
A pesar de que "Linux" se denomina en la jerga cotidiana al sistema operativo, este es en realidad sólo el Kernel (núcleo) del sistema. La verdadera denominación del sistema operativo es "GNU/Linux"
debido a que el resto del sistema (la parte fundamental de la
interacción entre el hardware y el usuario) se maneja con las
herramientas del proyecto GNU (www.gnu.org) y con entornos de escritorio (como GNOME), que también forma parte del proyecto GNU aunque tuvo un origen independiente. Como el Proyecto GNU destaca, GNU es una distribución, usándose el término sistema operativo en el sentido empleado en el ecosistema Unix, lo que en cualquier caso significa que Linux
es solo una pieza más dentro de GNU/Linux. Sin embargo, una parte
significativa de la comunidad, así como muchos medios generales y
especializados, prefieren utilizar el término Linux para referirse a la unión de ambos proyectos. Para más información consulte la sección "Denominación GNU/Linux" o el artículo "Controversia por la denominación GNU/Linux".
A las variantes de esta unión de programas y tecnologías, a las que
se les adicionan diversos programas de aplicación de propósitos
específicos o generales se las denomina distribuciones.
Su objetivo consiste en ofrecer ediciones que cumplan con las
necesidades de un determinado grupo de usuarios. Algunas de ellas son
especialmente conocidas por su uso en servidores y supercomputadoras.
donde tiene la cuota más importante del mercado. Según un informe de
IDC, GNU/Linux es utilizado por el 78% de los principales 500 servidores
del mundo, otro informe le da una cuota de mercado de 89% en los 500 mayores supercomputadores. Con menor cuota de mercado el sistema GNU/Linux también es usado en el segmento de las computadoras de escritorio, portátiles, computadoras de bolsillo, teléfonos móviles, sistemas embebidos, videoconsolas y otros dispositivos.
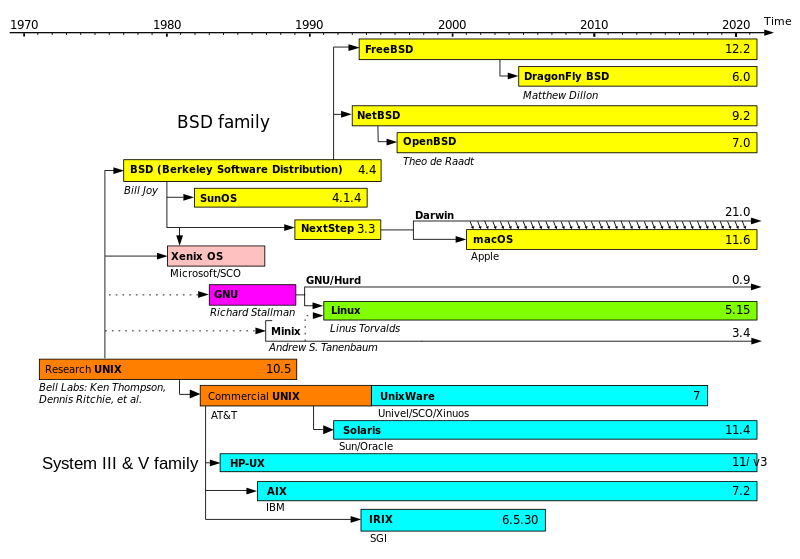
El nombre GNU, GNU's Not Unix (GNU no es Unix), viene de las herramientas básicas de sistema operativo creadas por el proyecto GNU, iniciado por Richard Stallman en 1983. El nombre Linux viene del núcleo Linux, inicialmente escrito por Linus Torvalds en 1991.
La contribución de GNU es la razón por la que existe controversia siempre y cuando a la hora de utilizar Linux o GNU/Linux para referirse al sistema operativo formado por las herramientas de GNU y el núcleo Linux en su conjunto.
El proyecto GNU, que se inició en 1983 por Richard Stallman; tiene como objetivo el desarrollo de un sistema operativo Unix completo y compuesto enteramente de software libre. La historia del núcleo Linux está fuertemente vinculada a la del proyecto GNU. En 1991 Linus Torvalds empezó a trabajar en un reemplazo no comercial para MINIX que más adelante acabaría siendo Linux.
Cuando Torvalds liberó la primera versión de Linux en 1992, el
proyecto GNU ya había producido varias de las herramientas fundamentales
para el manejo del sistema operativo, incluyendo un intérprete de comandos, una biblioteca C y un compilador, pero como el proyecto contaba con una infraestructura para crear su propio núcleo (o kernel), el llamado Hurd,
y este aún no era lo suficiente maduro para usarse, comenzaron a usar a
Linux a modo de continuar desarrollando el proyecto GNU, siguiendo la
tradicional filosofía de mantener cooperatividad entre desarrolladores.
El día en que se estime que Hurd es suficiente maduro y estable, será
llamado a reemplazar a Linux.
Entonces, el núcleo creado por Linus Torvalds, quien se encontraba por entonces estudiando la carrera de Ingeniería Informática en la Universidad de Helsinki, llenó el "espacio" final que había en el sistema operativo de GNU.
Entorno gráfico
GNU/Linux puede funcionar tanto en entorno gráfico como en modo consola.
La consola es común en distribuciones para servidores, mientras que la
interfaz gráfica está orientada al usuario final tanto de hogar como
empresarial. Asimismo, también existen los entornos de escritorio,
que son un conjunto de programas conformado por ventanas, iconos y
muchas aplicaciones que facilitan la utilización del computador. Los
escritorios más populares en GNU/Linux son: GNOME, KDE SC, LXDE y Xfce. En dispositivos móviles se encuentra Android, que funciona sobre el núcleo Linux, pero no usa las herramientas GNU. Intel anunció productos de consumo basados en MeeGo para mediados del 2011, por lo que es probable que este entorno tenga también una creciente importancia en los próximos años.
Como sistema de programación
La colección de utilidades para la programación de GNU es con diferencia la familia de compiladores más utilizada en este sistema operativo. Tiene capacidad para compilar C, C++, Java, Ada, Pascal,
entre otros muchos lenguajes. Además soporta diversas arquitecturas
mediante la compilación cruzada, lo que hace que sea un entorno adecuado
para desarrollos heterogéneos.
Hay varios entornos de desarrollo integrados disponibles para GNU/Linux incluyendo, Anjuta, KDevelop, Lazarus, Ultimate++, Code::Blocks, NetBeans IDE y Eclipse. También existen editores extensibles como Emacs o Vim.
GNU/Linux también dispone de capacidades para lenguajes de guion
(script), aparte de los clásicos lenguajes de programación de shell, o el de procesado de textos por patrones y expresiones regulares llamado awk, la mayoría de las distribuciones tienen instalado Python, Perl, PHP y Ruby.
Aplicaciones de usuario
Las aplicaciones para GNU/Linux se distribuyen principalmente en los formatos .deb y .rpm, los cuales fueron creados por los desarrolladores de Debian y Red Hat respectivamente. También existe la posibilidad de instalar aplicaciones a partir de código fuente en todas las distribuciones.
Software de código cerrado para GNU/Linux
Durante la etapa temprana había pocas aplicaciones de código cerrado para GNU/Linux. Con el tiempo se fueron portando programas no libres al sistema GNU/Linux, entre ellos Adobe Reader, Adobe Flash, Opera, entre otros.
Cuota de mercado
Numerosos estudios cuantitativos sobre software de código abierto
están orientados a temas como la cuota de mercado y la fiabilidad, y
ciertamente muchos de estos estudios examinan específicamente a
GNU/Linux.42
La medición "cuota de mercado" puede resultar inservible ya que es un
concepto basado en ventas comerciales (unidades materiales vendidas).
Por otro lado Linux es utilizado frecuentemente en servidores con acceso
público desde Internet por lo que la cuota de mercado es extremadamente
inferior a la cuota de uso. Baste notar, p.ej, que Facebook, Gmail,
LinkedIn o Yahoo funcionan sobre servidores GNU/Linux, de forma que aún
cuando estemos accediendo desde un navegador ejecutándose en
Windows/Mac, la aplicación real se está ejecutando en servidores Linux y
los datos están almacenándose igualmente en dichos servidores.
Hay varias empresas que comercializan soluciones basadas en GNU/Linux: IBM, Novell (SuSE), Red Hat (RHEL), Mandriva (Mandriva Linux), Rxart, Canonical Ltd. (Ubuntu), así como miles de PYMES que ofrecen productos o servicios basados en esta tecnología.
Aplicaciones
Supercomputadoras
Dentro del segmento de supercomputadoras,
a noviembre de 2012, el uso de este sistema ascendió al 93,8% de las
computadoras más potentes del mundo por su confiabilidad, seguridad y
libertad para modificar el código. De acuerdo con TOP500.org,
que lleva estadísticas sobre las 500 principales supercomputadoras del
mundo, a noviembre de 2012: 469 usaban una distribución basada en
GNU/Linux, 20 Unix, 7 mezclas, 1 BSD y 3 Windows.
Las primeras 37 supercomputadoras, incluidas la número 1, la Titan - Cray XK7 con 560.640 procesadores, utilizan distribuciones basadas en GNU/Linux.44
GNU/Linux, además de liderar el mercado de servidores de Internet
debido, entre otras cosas, a la gran cantidad de soluciones que tiene
para este segmento, tiene un crecimiento progresivo en computadoras de
escritorio y portátiles. Además, es el sistema base que se ha elegido
para el proyecto OLPC: One Laptop Per Child.
Para saber más sobre las arquitecturas soportadas, lea el artículo "Portabilidad del núcleo Linux y arquitecturas soportadas".
Teléfonos inteligentes y tabletas
Linux tiene un papel imprescindible en el territorio de los teléfonos inteligentes debido a que Android y meego lo utilizan. Actualmente Android es el sistema operativo predominante en los nuevos teléfonos inteligentes y su cuota de mercado mundial supera a iOS de Apple.
Fuerzas Armadas
El sistema operativo del General Atomics MQ-1 Predator está basado en GNU/Linux, así como el del Boeing P-8 Poseidon.
Denominación GNU/Linux
Evolución de los sistemas UNIX
Parte de la comunidad y numerosos medios prefieren denominar a esta combinación como Linux, aunque GNU/Linux (con las variantes GNU con Linux y GNU+Linux) es la denominación defendida por el Proyecto GNU y la FSF junto con otros desarrolladores y usuarios para el conjunto que utiliza el sistema operativo Linux en conjunto con las aplicaciones de sistema creadas por el proyecto GNU y por muchos otros proyectos de software.48 49
Desde 1984, Richard Stallman y muchos voluntarios están intentando crear un sistema operativo libre con un funcionamiento similar al UNIX, recreando todos los componentes necesarios para tener un sistema operativo funcional. A comienzos de los años 90, unos seis años desde el inicio del proyecto, GNU tenía muchas herramientas importantes listas, como editores de texto, compiladores, depuradores, intérpretes de comandos de órdenes etc., excepto por el componente central: el núcleo.
GNU tiene su propio proyecto de núcleo, llamado Hurd. Sin embargo, su desarrollo no continuó como se esperaba al aparecer el núcleo Linux. De esta forma se completaron los requisitos mínimos y surgió el sistema operativo GNU que utilizaba el núcleo Linux.
El principal argumento de los defensores de la denominación GNU/Linux
es resolver la posible confusión que se puede dar entre el núcleo
(Linux) y gran parte de las herramientas básicas del resto del sistema
operativo (GNU), y del sistema completo que usualmente se usa como
combinación de GNU, Linux, y otros proyectos de software. Además,
también se espera que con el uso del nombre GNU, se dé al proyecto GNU el reconocimiento por haber creado las herramientas de sistema imprescindibles para ser un sistema operativo compatible con UNIX,
y se destaque la cualidad de estar compuesto sólo por software libre.
La primera distribución que incluyó el GNU en su nombre fue Yggdrasyl en 1992, donde aparecía como Linux/GNU/X. La FSF denominó a este sistema "Linux" hasta al menos junio de 1994 y recién a partir de enero de 1995 empezó a llamarlo "GNU/Linux" (también GNU+Linux y lignux, términos que han caído en desuso a instancias del propio Stallman).