BLOQUEO MUTUO
En sistemas operativos, el bloqueo mutuo (también conocido como interbloqueo, traba mortal, deadlock, abrazo mortal) es el bloqueo permanente de un conjunto de procesos o hilos de ejecución en un sistema concurrente
que compiten por recursos del sistema o bien se comunican entre ellos. A
diferencia de otros problemas de concurrencia de procesos, no existe
una solución general para los interbloqueos.
Todos los interbloqueos surgen de necesidades que no pueden ser
satisfechas, por parte de dos o más procesos. En la vida real, un
ejemplo puede ser el de dos niños que intentan jugar al arco y flecha,
uno toma el arco, el otro la flecha. Ninguno puede jugar hasta que
alguno libere lo que tomó.
En el siguiente ejemplo, dos procesos compiten por dos recursos que
necesitan para funcionar, que sólo pueden ser utilizados por un proceso a
la vez. El primer proceso obtiene el permiso de utilizar uno de los
recursos (adquiere el lock
sobre ese recurso). El segundo proceso toma el lock del otro recurso, y
luego intenta utilizar el recurso ya utilizado por el primer proceso,
por lo tanto queda en espera. Cuando el primer proceso a su vez intenta
utilizar el otro recurso, se produce un interbloqueo, donde los dos
procesos esperan la liberación del recurso que utiliza el otro proceso.
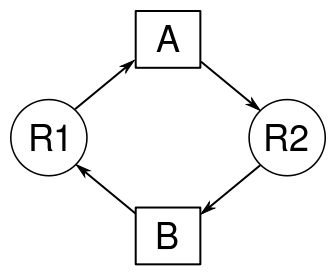
Representación de Bloqueos Mutuos usando grafos
El Bloqueo mutuo también puede ser representado usando grafos
dirigidos, donde el proceso es representado por un cuadrado y el
recurso, por un círculo. Cuando un proceso solicita un recurso, una
flecha es dirigida del círculo al cuadrado. Cuando un recurso es
asignado a un proceso, una flecha es dirigida del cuadrado al círculo.
En la figura del ejemplo, se pueden ver dos procesos diferentes (A y B), cada uno con un recurso diferente asignado (R1 y R2). En este ejemplo clásico de bloqueo mutuo, es fácilmente visible la condición de espera circular en la que los procesos se encuentran, donde cada uno solicita un recurso que está asignado a otro proceso.
Condiciones necesarias
También conocidas como condiciones de Coffman por su primera descripción en 1971 en un artículo escrito por E. G. Coffman.
Estas condiciones deben cumplirse simultáneamente y no son totalmente independientes entre ellas.
Sean los procesos P0, P1, ..., Pn y los recursos R0, R1, ..., Rm:
- Condición de exclusión mutua: existencia de al menos de un recurso compartido por los procesos, al cual sólo puede acceder uno simultáneamente.
- Condición de retención y espera: al menos un proceso Pi ha adquirido un recurso Ri, y lo retiene mientras espera al menos un recurso Rj que ya ha sido asignado a otro proceso.
- Condición de no expropiación: los recursos no pueden ser expropiados por los procesos, es decir, los recursos sólo podrán ser liberados voluntariamente por sus propietarios.
- Condición de espera circular: dado el conjunto de procesos P0...Pm(subconjunto del total de procesos original),P0 está esperando un recurso adquirido por P1, que está esperando un recurso adquirido por P2,... ,que está esperando un recurso adquirido por Pm, que está esperando un recurso adquirido por P0. Esta condición implica la condición de retención y espera.
Evitando bloqueos mutuos
Los bloqueos mutuos pueden ser evitados si se sabe cierta información
sobre los procesos antes de la asignación de recursos. Para cada
petición de recursos, el sistema controla si satisfaciendo el pedido
entra en un estado inseguro, donde puede producirse un bloqueo mutuo. De
esta forma, el sistema satisface los pedidos de recursos solamente si
se asegura que quedará en un estado seguro. Para que el sistema sea
capaz de decidir si el siguiente estado será seguro o inseguro, debe
saber por adelantado y en cualquier momento el número y tipo de todos
los recursos en existencia, disponibles y requeridos. Existen varios
algoritmos para evitar bloqueos mutuos:
- Algoritmo del banquero, introducido por Dijkstra.
- Algoritmo de grafo de asignación de recursos.
- Algoritmo de Seguridad.
- Algoritmo de solicitud de recursos.
Hilo de ejecución
un hilo de ejecución o subproceso es la unidad de procesamiento más pequeña que puede ser planificada por un sistema operativo.
La creación de un nuevo hilo es una característica que permite a una aplicación realizar varias tareas a la vez (concurrentemente).
Los distintos hilos de ejecución comparten una serie de recursos tales
como el espacio de memoria, los archivos abiertos, situación de
autenticación, etc. Esta técnica permite simplificar el diseño de una
aplicación que debe llevar a cabo distintas funciones simultáneamente.
Un hilo es simplemente una tarea que puede ser ejecutada al mismo tiempo con otra tarea.
Los hilos de ejecución que comparten los mismos recursos, sumados a estos recursos, son en conjunto conocidos como un proceso.
El hecho de que los hilos de ejecución de un mismo proceso compartan
los recursos hace que cualquiera de estos hilos pueda modificar éstos.
Cuando un hilo modifica un dato en la memoria, los otros hilos acceden a
ese dato modificado inmediatamente.
Lo que es propio de cada hilo es el contador de programa, la pila de ejecución y el estado de la CPU (incluyendo el valor de los registros).
El proceso sigue en ejecución mientras al menos uno de sus hilos de
ejecución siga activo. Cuando el proceso finaliza, todos sus hilos de
ejecución también han terminado. Asimismo en el momento en el que todos
los hilos de ejecución finalizan, el proceso no existe más y todos sus
recursos son liberados.
Un ejemplo de la utilización de hilos es tener un hilo atento a la interfaz gráfica
(iconos, botones, ventanas), mientras otro hilo hace una larga
operación internamente. De esta manera el programa responde de manera
más ágil a la interacción con el usuario. También pueden ser utilizados
por una aplicación servidora para dar servicio a múltiples clientes.
Diferencias entre hilos y procesos
Los hilos se distinguen de los tradicionales procesos en que los
procesos son generalmente independientes, llevan bastante información
de estados, e interactúan sólo a través de mecanismos de comunicación dados por el sistema. Por otra parte, muchos hilos generalmente comparten otros recursos de forma directa. En muchos de los sistemas operativos
que dan facilidades a los hilos, es más rápido cambiar de un hilo a
otro dentro del mismo proceso, que cambiar de un proceso a otro. Este
fenómeno se debe a que los hilos comparten datos y espacios de
direcciones, mientras que los procesos, al ser independientes, no lo
hacen. Al cambiar de un proceso a otro el sistema operativo (mediante el
dispatcher) genera lo que se conoce como overhead, que es tiempo desperdiciado por el procesador para realizar un cambio de contexto (context switch), en este caso pasar del estado de ejecución (running) al estado de espera (waiting)
y colocar el nuevo proceso en ejecución. En los hilos, como pertenecen a
un mismo proceso, al realizar un cambio de hilo el tiempo perdido es
casi despreciable.
Funcionalidad de los hilos
Al igual que los procesos, los hilos poseen un estado de ejecución y
pueden sincronizarse entre ellos para evitar problemas de compartición
de recursos. Generalmente, cada hilo tiene una tarea especifica y
determinada, como forma de aumentar la eficiencia del uso del
procesador.
Estados de un hilo
Los principales estados de los hilos son: Ejecución, Listo y
Bloqueado. No tiene sentido asociar estados de suspensión de hilos ya
que es un concepto de proceso. En todo caso, si un proceso está
expulsado de la memoria principal (RAM), todos sus hilos deberán estarlo ya que todos comparten el espacio de direcciones del proceso.
Cambio de estados
- Creación: Cuando se crea un proceso se crea un hilo para ese proceso. Luego, este hilo puede crear otros hilos dentro del mismo proceso, proporcionando un puntero de instrucción y los argumentos del nuevo hilo. El hilo tendrá su propio contexto y su propio espacio de la columna, y pasará al final de los Listos.
- Bloqueo: Cuando un hilo necesita esperar por un suceso, se bloquea (salvando sus registros de usuario, contador de programa y punteros de pila). Ahora el procesador podrá pasar a ejecutar otro hilo que esté al principio de los Listos mientras el anterior permanece bloqueado.
- Desbloqueo: Cuando el suceso por el que el hilo se bloqueó se produce, el mismo pasa a la final de los Listos.
- Terminación: Cuando un hilo finaliza se liberan tanto su contexto como sus columnas.
Sincronización de hilos
Todos los hilos comparten el mismo espacio de direcciones y otros
recursos como pueden ser archivos abiertos. Cualquier modificación de un
recurso desde un hilo afecta al entorno del resto de los hilos del
mismo proceso. Por lo tanto, es necesario sincronizar la actividad de
los distintos hilos para que no interfieran unos con otros o corrompan
estructuras de datos.
Una ventaja de la programación multihilo es que los programas operan con mayor velocidad en sistemas de computadores con múltiples CPUs (sistemas multiprocesador o a través de grupo de máquinas) ya que los hilos del programa se prestan verdaderamente para la ejecución concurrente. En tal caso el programador
necesita ser cuidadoso para evitar condiciones de carrera (problema que
sucede cuando diferentes hilos o procesos alteran datos que otros
también están usando), y otros comportamientos no intuitivos. Los hilos
generalmente requieren reunirse para procesar los datos en el orden
correcto. Es posible que los hilos requieran de operaciones atómicas
para impedir que los datos comunes sean cambiados o leídos mientras
estén siendo modificados, para lo que usualmente se utilizan los semáforos. El descuido de esto puede generar interbloqueo.
Formas de multihilos
Los sistemas operativos generalmente implementan hilos de dos maneras:
- Multihilo apropiativo: permite al sistema operativo determinar cuándo debe haber un cambio de contexto. La desventaja de esto es que el sistema puede hacer un cambio de contexto en un momento inadecuado, causando un fenómeno conocido como inversión de prioridades y otros problemas.
- Multihilo cooperativo: depende del mismo hilo abandonar el control cuando llega a un punto de detención, lo cual puede traer problemas cuando el hilo espera la disponibilidad de un recurso.
Implementaciones
Hay dos grandes categorías en la implementación de hilos:
- Hilos a nivel de usuario.
- Hilos a nivel de kernel.
También conocidos como ULT (user level thread) y KLT (kernel level thread)
Hilos a nivel de usuario (ULT)
En una aplicación ULT pura, todo el trabajo de gestión de hilos lo
realiza la aplicación y el núcleo o kernel no es consciente de la
existencia de hilos. Es posible programar una aplicación como multihilo
mediante una biblioteca de hilos. La misma contiene el código para crear
y destruir hilos, intercambiar mensajes y datos entre hilos, para
planificar la ejecución de hilos y para salvar y restaurar el contexto
de los hilos.
Todas las operaciones descritas se llevan a cabo en el espacio de
usuario de un mismo proceso. El kernel continua planificando el proceso
como una unidad y asignándole un único estado (Listo, bloqueado, etc.).
Ventajas de los ULT
- El intercambio de los hilos no necesita los privilegios del modo kernel, porque todas las estructuras de datos están en el espacio de direcciones de usuario de un mismo proceso. Por lo tanto, el proceso no debe cambiar a modo kernel para gestionar hilos. Se evita la sobrecarga de cambio de modo y con esto el sobrecoste u overhead.
- Se puede realizar una planificación específica. Dependiendo de que aplicación sea, se puede decidir por una u otra planificación según sus ventajas.
- Los ULT pueden ejecutar en cualquier sistema operativo. La biblioteca de hilos es un conjunto compartido.
Desventajas de los ULT
- En la mayoría de los sistemas operativos las llamadas al sistema (System calls) son bloqueantes. Cuando un hilo realiza una llamada al sistema, se bloquea el mismo y también el resto de los hilos del proceso.
- En una estrategia ULT pura, una aplicación multihilo no puede aprovechar las ventajas de los multiprocesadores. El núcleo asigna un solo proceso a un solo procesador, ya que como el núcleo no interviene, ve al conjunto de hilos como un solo proceso.
Una solución al bloqueo mediante a llamadas al sistema es usando la técnica de jacketing,
que es convertir una llamada bloqueante en no bloqueante; esto se
consigue comprobando previamente si la llamada al sistema bloqueará el
proceso o no. Si es así, se bloquea el hilo y se pasa el control a otro
hilo. Más adelante se reactiva el hilo bloqueado y se vuelve a realizar
la comprobación, hasta que se pueda realizar la llamada al sistema sin
que el proceso completo sea bloqueado.
Hilos a nivel de núcleo (KLT)
En una aplicación KLT pura, todo el trabajo de gestión de hilos lo
realiza el kernel. En el área de la aplicación no hay código de gestión
de hilos, únicamente un API (interfaz de programas de aplicación) para la gestión de hilos en el núcleo. Windows 2000, Linux y OS/2
utilizan este método. Linux utiliza un método muy particular en el que
no hace diferencia entre procesos e hilos. Para Linux, si varios
procesos creados con la llamada al sistema "clone" comparten el mismo
espacio de direcciones virtuales, el sistema operativo los trata como
hilos, y lógicamente son manejados por el kernel.
Ventajas de los KLT
- El kernel puede planificar simultáneamente múltiples hilos del mismo proceso en múltiples procesadores.
- Si se bloquea un hilo, puede planificar otro del mismo proceso.
- Las propias funciones del kernel pueden ser multihilo.
Desventajas de los KLT
- El paso de control de un hilo a otro precisa de un cambio de modo.
Combinaciones ULT y KLT
Algunas distribuciones de linux y derivados de UNIX ofrecen la combinación de ULTss y KLT, como Solaris, Ubuntu y Fedora.
La creación de hilos, así como la mayor parte de la planificación y
sincronización de los hilos de una aplicación se realiza por completo en
el espacio de usuario. Los múltiples ULT de una sola aplicación se
asocian con varios KLT. El programador puede ajustar el número de KLT
para cada aplicación y máquina para obtener el mejor resultado global.
En un método combinado, los múltiples hilos de una aplicación se
pueden ejecutar en paralelo en múltiples procesadores y las llamadas al
sistema bloqueadoras no necesitan bloquear todo el proceso.
No hay comentarios.:
Publicar un comentario